|
|
|
| Home | Initium | Angiogenesis | FAQ |
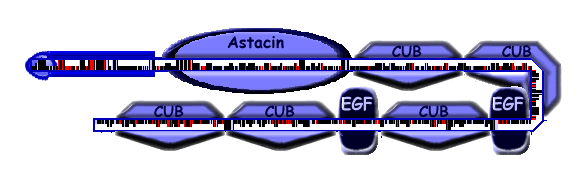
| TEM domain structure |
|---|
|
|
|
|
| TEM Sequence Analysis |
|---|
| name | from | to | source/E | description |
|---|---|---|---|---|
| SignalP | 1 | 23 | ||
| PROPEP | 2 | 120 | SEG45 | LCR(LAD-RS). This propeptide sequence is cleaved to give the active protease. |
| Astacin | 128 | 321 | Pfam, E = 3.5e-115 | The zinc_protease family M12A domain is the catalytic domain, with zinc binding motif. |
| CUB | 322 | 431 | Pfam, E = 7.9e-58 | The CUB domain of TEM25 contains four conserved cysteines that are proposed to form two disulfide bridges (C1-C2, C3-C4). |
| CUB | 435 | 544 | Pfam, E = 9.6e-65 | The CUB domain of TEM25 contains four conserved cysteines that are proposed to form two disulfide bridges (C1-C2, C3-C4). |
| EGF EGFCa |
551 | 587 | Pfam, E = 1.7e-06 | |
| CUB | 591 | 700 | Pfam, E = 2.1e-59 | The CUB domain of TEM25 contains four conserved cysteines that are proposed to form two disulfide bridges (C1-C2, C3-C4). |
| EGF EGFCa |
707 | 742 | Pfam,E = 0.00011 | |
| CUB | 747 | 856 | Pfam, E = 2.7e-58 | The CUB domain of TEM25 contains four conserved cysteines that are proposed to form two disulfide bridges (C1-C2, C3-C4). |
| CUB | 860 | 973 | Pfam,E = 1.7e-48 | The CUB domain of TEM25 contains four conserved cysteines that are proposed to form two disulfide bridges (C1-C2, C3-C4). |
| 986 |
| Remarks |
|---|
| Sequence Information |
|---|
| TEM | TEM25 | ||||||||
Reliability of Gen2Tag mapping |
|
||||||||
| Analysis |
|
||||||||
| Protein Description |
|
||||||||
| Protein Sequence |
MPGVARLPLLLGLLLLPRPGRPLDLADYTYDLAEEDDSEPLNYKDPCKAAAFLGDIALDEEDLRAFQVQQ AVDLRRHTARKSSIKAAVPGNTSTPSCQSTNGQPQRGACGRWRGRSRSRRAATSRPERVWPDGVIPFVIG GNFTGSQRAVFRQAMRHWEKHTCVTFLERTDEDSYIVFTYRPCGCCSYVGRRGGGPQAISIGKNCDKFGI VVHELGHVVGFWHEHTRPDRDRHVSIVRENIQPGQEYNFLKMEPQEVESLGETYDFDSIMHYARNTFSRG IFLDTIVPKYEVNGVKPPIGQRTRLSKGDIAQARKLYKCPACGETLQDSTGNFSSPEYPNGYSAHMHCVW RISVTPGEKIILNFTSLDLYRSRLCWYDYVEVRDGFWRKAPLRGRFCGSKLPEPIVSTDSRLWVEFRSSS NWVGKGFFAVYEAICGGDVKKDYGHIQSPNYPDDYRPSKVCIWRIQVSEGFHVGLTFQSFEIERHDSCAY DYLEVRDGHSESSTLIGRYCGYEKPDDIKSTSSRLWLKFVSDGSINKAGFAVNFFKEVDECSRPNRGGCE QRCLNTLGSYKCSCDPGYELAPDKRRCEAACGGFLTKLNGSITSPGWPKEYPPNKNCIWQLVAPTQYRIS LQFDFFETEGNDVCKYDFVEVRSGLTADSKLHGKFCGSEKPEVITSQYNNMRVEFKSDNTVSKKGFKAHF FSDKDECSKDNGGCQQDCVNTFGSYECQCRSGFVLHDNKHDCKEAGCDHKVTSTSGTITSPNWPDKYPSK KECTWAISSTPGHRVKLTFMEMDIESQPECAYDHLEVFDGRDAKAPVLGRFCGSKKPEPVLATGSRMFLR FYSDNSVQRKGFQASHATECGGQVRADVKTKDLYSHAQFGDNNYPGGVDCEWVIVAEEGYGVELVFQTFE VEEETDCGYDYMELFDGYDSTAPRLGRYCGSGPPEEVYSAGDSVLVKFHSDDTITKKGFHLRYTSTKFQD TLHSRK |
||||||||
|
SAGE-Tag |
CATG-TCCCCCAGGAG | ||||||||
| EST/cluster Description |
|
||||||||
| EST/cluster Sequence |
ATGCCCGGCGTGGCCCGCCTGCCGCTGCTGCTCGGGCTGCTGCTGCTCCCGCGTCCCGGCCGGCCGCTGG ACTTGGCCGACTACACCTATGACCTGGCGGAGGAGGACGACTCGGAGCCCCTCAACTACAAAGACCCCTG CAAGGCGGCTGCCTTTCTTGGGGACATTGCCCTGGACGAAGAGGACCTGAGGGCCTTCCAGGTACAGCAG GCTGTGGATCTCAGACGGCACACAGCTCGTAAGTCCTCCATCAAAGCTGCAGTTCCAGGAAACACTTCTA CCCCCAGCTGCCAGAGCACCAACGGGCAGCCTCAGAGGGGAGCCTGTGGGAGATGGAGAGGTAGATCCCG TAGCCGGCGGGCGGCGACGTCCCGACCAGAGCGTGTGTGGCCCGATGGGGTCATCCCCTTTGTCATTGGG GGAAACTTCACTGGTAGCCAGAGGGCAGTCTTCCGGCAGGCCATGAGGCACTGGGAGAAGCACACCTGTG TCACCTTCCTGGAGCGCACTGACGAGGACAGCTATATTGTGTTCACCTATCGACCTTGCGGGTGCTGCTC CTACGTGGGTCGCCGCGGCGGGGGCCCCCAGGCCATCTCCATCGGCAAGAACTGTGACAAGTTCGGCATT GTGGTCCACGAGCTGGGCCACGTCGTCGGCTTCTGGCACGAACACACTCGGCCAGACCGGGACCGCCACG TTTCCATCGTTCGTGAGAACATCCAGCCAGGGCAGGAGTATAACTTCCTGAAGATGGAGCCTCAGGAGGT GGAGTCCCTGGGGGAGACCTATGACTTCGACAGCATCATGCATTACGCTCGGAACACATTCTCCAGGGGC ATCTTCCTGGATACCATTGTCCCCAAGTATGAGGTGAACGGGGTGAAACCTCCCATTGGCCAAAGGACAC GGCTCAGCAAGGGGGACATTGCCCAAGCCCGCAAGCTTTACAAGTGCCCAGCCTGTGGAGAGACCCTGCA AGACAGCACAGGCAACTTCTCCTCCCCTGAATACCCCAATGGCTACTCTGCTCACATGCACTGCGTGTGG CGCATCTCTGTCACACCCGGGGAGAAGATCATCCTGAACTTCACGTCCCTGGACCTGTACCGCAGCCGCC TGTGCTGGTACGACTATGTGGAGGTCCGAGATGGCTTCTGGAGGAAGGCGCCCCTCCGAGGCCGCTTCTG CGGGTCCAAACTCCCTGAGCCTATCGTCTCCACTGACAGCCGCCTCTGGGTTGAATTCCGCAGCAGCAGC AATTGGGTTGGAAAGGGCTTCTTTGCAGTCTACGAAGCCATCTGCGGGGGTGATGTGAAAAAGGACTATG GCCACATTCAATCGCCCAACTACCCAGACGATTACCGGCCCAGCAAAGTCTGCATCTGGCGGATCCAGGT GTCTGAGGGCTTCCACGTGGGCCTCACATTCCAGTCCTTTGAGATTGAGCGCCACGACAGCTGTGCCTAC GACTATCTGGAGGTGCGCGACGGGCACAGTGAGAGCAGCACCCTCATCGGGCGCTACTGTGGCTATGAGA AGCCTGATGACATCAAGAGCACGTCCAGCCGCCTCTGGCTCAAGTTCGTCTCTGACGGGTCCATTAACAA AGCGGGCTTTGCCGTCAACTTTTTCAAAGAGGTGGACGAGTGCTCTCGGCCCAACCGCGGGGGCTGTGAG CAGCGGTGCCTCAACACCCTGGGCAGCTACAAGTGCAGCTGTGACCCCGGGTACGAGCTGGCCCCAGACA AGCGCCGCTGTGAGGCTGCTTGTGGCGGATTCCTCACCAAGCTCAACGGCTCCATCACCAGCCCGGGCTG GCCCAAGGAGTACCCCCCCAACAAGAACTGCATCTGGCAGCTGGTGGCCCCCACCCAGTACCGCATCTCC CTGCAGTTTGACTTCTTTGAGACAGAGGGCAATGATGTGTGCAAGTACGACTTCGTGGAGGTGCGCAGTG GACTCACAGCTGACTCCAAGCTGCATGGCAAGTTCTGTGGTTCTGAGAAGCCCGAGGTCATCACCTCCCA GTACAACAACATGCGCGTGGAGTTCAAGTCCGACAACACCGTGTCCAAAAAGGGCTTCAAGGCCCACTTC TTCTCAGACAAGGACGAGTGCTCCAAGGATAACGGCGGCTGCCAGCAGGACTGCGTCAACACGTTCGGCA GTTATGAGTGCCAATGCCGCAGTGGCTTCGTCCTCCATGACAACAAGCACGACTGCAAAGAAGCCGGCTG TGACCACAAGGTGACATCCACCAGTGGTACCATCACCAGCCCCAACTGGCCTGACAAGTATCCCAGCAAG AAGGAGTGCACGTGGGCCATCTCCAGCACCCCCGGGCACCGGGTCAAGCTGACCTTCATGGAGATGGACA TCGAGTCCCAGCCTGAGTGTGCCTACGACCACCTAGAGGTGTTCGACGGGCGAGACGCCAAGGCCCCCGT CCTCGGCCGCTTCTGTGGGAGCAAGAAGCCCGAGCCCGTCCTGGCCACAGGCAGCCGCATGTTCCTGCGC TTCTACTCAGATAACTCGGTCCAGCGAAAGGGCTTCCAGGCCTCCCACGCCACAGAGTGCGGGGGCCAGG TACGGGCAGACGTGAAGACCAAGGACCTTTACTCCCACGCCCAGTTTGGCGACAACAACTACCCTGGGGG TGTGGACTGTGAGTGGGTCATTGTGGCCGAGGAAGGCTACGGCGTGGAGCTCGTGTTCCAGACCTTTGAG GTGGAGGAGGAGACCGACTGCGGCTATGACTACATGGAGCTCTTCGACGGCTACGACAGCACAGCCCCCA GGCTGGGGCGCTACTGTGGCTCAGGGCCTCCTGAGGAGGTGTACTCGGCGGGAGATTCTGTCCTGGTGAA GTTCCACTCGGATGACACCATCACCAAAAAAGGTTTCCACCTGCGATACACCAGCACCAAGTTCCAGGAC ACACTCCACAGCAGGAAGTGACCACTGCCTGAGCAGGGGCGGGGACTGGAGCCTGCTGCCCTTGGTCGCC TAGACTGGATAGTGGGGGTGGGCGGAACGCAACGCACCATCCCTCTCCCCCAGGCCCCAGGACCTGCAGG GCCAATGGCCTGGTGAGACTGTCCATAGGAGGTGGGGGAACTGGACTCCGGCATAAGCCACTTCCCCACA AACCCCCACCAGCAAGGGGCTGGGGCCAGGGAGCAGAGCTTCCACAAGACATTTCGAAGTCATCATTCCT CTCTTAGGGGGCCCTGCCTGGTGGCAAGAGGGAATGTCAGCAGGACCCCATCGCCATCCCTGTGTCTCTA CACGCTGTATTGTGTATCACCGGGGGCATTATTTTCATTGTAATGTTCATTTCCCACCCCTGCTCCAGCC TCGATTTGGTTTTATTTTGAGCCCCCATTCCACCACAGTTTCCTGGGGCACAAGTGTCTGTGCATGTCCC CCAGGAGCCACCGTGGGGAGCCGATGGGGAGGGGATGGAGAAACAAGACAGGGCTTCTCTCAGCCCATGG CCGGTCAGCCACACCAGGGCACCGCAGCCAATAAACCGAAAGTGTT |
||||||||
| Genomic Sequence Description | |||||||||
| Genomic Sequence |
|
| Literature |
|---|
| PubMed: 10806203 | Bone morphogenetic protein 1 is an extracellular processing enzyme of the laminin 5 gamma 2 chain. Amano S, Scott IC, Takahara K, Koch M, Champliaud MF, Gerecke DR, Keene DR, Hudson DL, Nishiyama T, Lee S, Greenspan DS, Burgeson RE J Biol Chem 2000 Jul 28;275(30):22728-35 |
| PubMed: 9524360 | Procollagen N-proteinase and procollagen C-proteinase. Two unusual metalloproteinases that are essential for procollagen processing probably have important roles in development and cell signaling. Prockop DJ, Sieron AL, Li SW. Matrix Biol 1998 Feb;16(7):399-408 |
| PubMed: 9247707 | Hatakeyama S, Gao YH, Ohara-Nemoto Y, Kataoka H, Satoh M. Expression of bone morphogenetic proteins of human neoplastic epithelial cells. Biochem Mol Biol Int. 1997 Jul;42(3):497-505. |
| PubMed: 7670368 | The astacin family of metalloendopeptidases. Bond JS, Beynon R J. Protein Sci. 1995 Jul;4(7):1247-61. |
| PubMed: 7798260 | Bone morphogenetic protein-1 and a mammalian tolloid homologue (mTld) are encoded by alternatively spliced transcripts which are differentially expressed in some tissues K Takahara, GE Lyons, and DS Greenspan J. Biol. Chem. 1994 269: 32572-32578. |
| PubMed: 8510165 | The CUB domain. A widespread module in developmentally regulated proteins. Bork P, Beckmann G. J Mol Biol. 1993 May 20;231(2):539-45. |
| Home | Initium | Angiogenesis | FAQ |